A Distant View of English Journal, 1912-2012
Jason Palmeri & Ben McCorkle

METHODOLOGY
Like many in the field, our previous historical work (McCorkle, 2012; Palmeri, 2012) employed narrative case study methodologies that relied primarily on close, contextual readings of key representative texts from the past. Yet, whenever we offered our textual exegeses of selected historical documents, we always were conscious of how much material we left on the table—how limited we were in our ability to make even tentative claims about larger trends spanning longer time periods. When we both decided to collaborate on investigating technological pedagogies in 100 years of English Journal, we quickly found that our traditional methods of close reading were not up to the task of making sense of the copious amount of potentially relevant texts we found in this archive. To answer the questions we had about how the media ecology of English studies has evolved over time, we needed to adopt a more capacious and distant methodology of reading.
Distant Reading Methodologies
Our methodology for this project has been inspired by Franco Moretti's (2000; 2013) theory of distant reading and how it has been adapted and applied by rhetoric and composition scholars (Gries, 2017; Miller, 2015; Mueller, 2012a; Mueller, 2012b). Challenging the traditional emphasis on close reading, Moretti (2000) argued on behalf of a methodology that instead privileges distance:
where distance [...] is a condition of knowledge: it allows you to focus on units that are much smaller or much larger than the text: devices, themes, tropes—or genres and systems. And if, between the very small and the very large, the text itself disappears, well, it is one of those cases when one can justifiably say, less is more. If we want to understand the system in its entirety, we must accept losing something. (p. 57)
If we remain too committed to teasing out every implication we can find in an individual text, we often lose sight of the broader systems and historical evolutions within which that text is embedded. Although our project engages very different kinds of texts and questions than Moretti's work in literary scholarship, we nevertheless were inspired by Moretti's methodology to focus our reading procedures less on interpreting the complexities of individual texts and more on quantitatively describing and visualizing how new media English pedagogies evolved over time.
Although Moretti's distant reading methodology was designed with literary texts in mind, scholars in composition and rhetoric have adapted "distant reading" and related data-driven methodologies to explore the disciplinarity of composition studies. In recent years, compositionists have shone new light on the disciplinary formation and evolution of our field by systematically coding and visualizing such historical archives as Conference on College Composition and Communication (CCCC) chair speeches (Mueller, 2012a), College Composition and Communication (CCC) article citations (Mueller, 2012b), rhetoric and composition dissertations (Miller, 2014; Miller, 2015), Modern Language Association (MLA) job advertisements (Lauer, 2013; Lauer, 2014), and disciplinary social networks (Miller, Licastro, & Belli, 2016). We were particularly inspired by Derek Mueller's (2012a) CCC article "Grasping Rhetoric and Composition by Its Long Tail," in which he generates a series of charts, bar graphs, and line graphs depicting changes in citation practices over 25 years, demonstrating how the field has become more diverse over time. As Mueller argued, "graphs help us see with fresh perspective continually unfolding tensions among specialization, the interdisciplinary reach of rhetoric and composition, and the challenges these present to newcomers to the scholarly conversation" (p. 196). Extending Moretti's work on data visualization to disciplinary histories of composition, Mueller's work "demonstrate[s] how graphs can function as a productive, suasive abstracting practice" (p. 196). We've also been inspired by Laurie Gries' (2017) recent Kairos webtext that demonstrated how robustly interactive data visualizations can help use re-see the circulation of texts. Like Gries and Mueller, we similarly seek to use data visualizations to reveal hidden trends in large archives—contending that our interactive, visual graphs can help us engage historical questions that we could not ask if we had limited our historical methodology to composing with alphabetic text alone.
As we refined our distant reading methodology for this project, we were also influenced by Mark Faust and Mark Dressman's (2009) historical work on poetry pedagogies in English Journal because it offered a model designed to uncover information similar in scale and sentiment to our own. In their study of poetry articles in English Journal from 1912 to 2005, Faust and Dressman located articles relevant to poetry by skimming the titles and content of each issue, managing their collaboration by reading and systematically coding alternate years (p. 117). They frequently conferred about their coding procedures and refined their coding scheme as they went through the years, relying on grounded theory methods (Corbin & Strauss, 2000). Major distinctions emerged between what Faust and Dressman labeled "formalist" (i.e., canonical and analytical) and "populist" (i.e, more playful or experimental) approaches to teaching poetry (p. 117). The authors plotted references to teaching poetry along a timeline in order to demonstrate the crests and troughs of these two categories over time (p. 121), allowing them to discover some surprising trends as they worked through the corpus. For example, Faust and Dressman demonstrated the prevalence of the populist approach to teaching poetry during the heyday of the new critical movement—a period that the pair had thought would trend towards more formalist pedagogy given new criticism's view of poems as "timeless, self-contained, precious objects" of study (pp. 116–117). In this way, Faust and Dressman's work inspired us by demonstrating how collaborative systematic coding of a large time period of English Journal can challenge common assumptions we often make about the field of English studies.
Methods of Locating & Coding Articles
Adapting Faust and Dressman's approach for gathering and analyzing data, we reviewed titles of the first 100 years of English Journal articles—sequentially and chronologically—in JSTOR (and once we exhausted the archives there, the National Council of Teachers of English [NCTE] website). We flagged and subsequently read those that explicitly mentioned media or technology in the title. In addition to flagging obvious articles that highlighted technological media in their titles, we followed up with a second-pass review of ambiguous titles that might also allude to our subject; for example, a title such as "Vitalizing Literature Study" (Coulter, 1912) was ambiguous so we opened the PDF, read it, and discovered that it addressed the use of the lantern (a precursor to the overhead projector) to display imagery associated with literary texts. Although we recognize that the book, the pencil, and the pen are all technologies (Baron, 2009; Eisenstein, 1979; Ong, 1982), we did not track mentions of these tools as they are ubiquitous in English studies scholarship and doing so would have made our corpus too large to be manageable. Although we did not code articles that focused on students reading print books or writing hand-written texts, we did code articles that described students and teachers actively using various print-based production technologies such as typewriters, printing presses, and photocopiers—though explicit discussion of these print tools was less common than we initially expected. In total, our corpus includes 766 individual articles and columns.
At the outset of our project, we developed a tentative coding scheme to categorize the most prevalent pedagogical orientations and ideological commonplaces we noticed in the articles. We developed this initial coding scheme based on our shared reading and conversation about approximately 50 articles in the archive from diverse decades. We then practiced systematically applying the scheme by both reading and coding three sample years' worth of articles. On the few occassions that we encountered an article that we found difficult to categorize, we discussed it and reached consensus about how it should be coded. Having devised and refined our coding scheme, we then alternated coding years of the journal (conferring with each other periodically if we encountered questions about how to code a particular text).
First, we categorized each article we read as either focused on teaching "media reception" or "media production." Articles focused on "media reception" emphasized teaching students to critically analyze, appreciate, and/or reflect about media texts; for example, we coded as reception articles that engaged students in having a class discussion of a film (Turner, 1931), writing a paper summarizing events in a television news broadcast (Hainfeld, 1953), or analyzing the credibility of a website (Gardner, Benham, & Newell, 1999). By contrast, "media production" articles emphasized students composing "new media" texts using whatever tools they had at hand. For example, an article about students and teachers collaborating with a local radio station to produce radio broadcasts was coded as "media production" (Nelson, 1939), but so was an article about students writing and performing a radio script for a live audience using a replica microphone (Campbell, 1936).
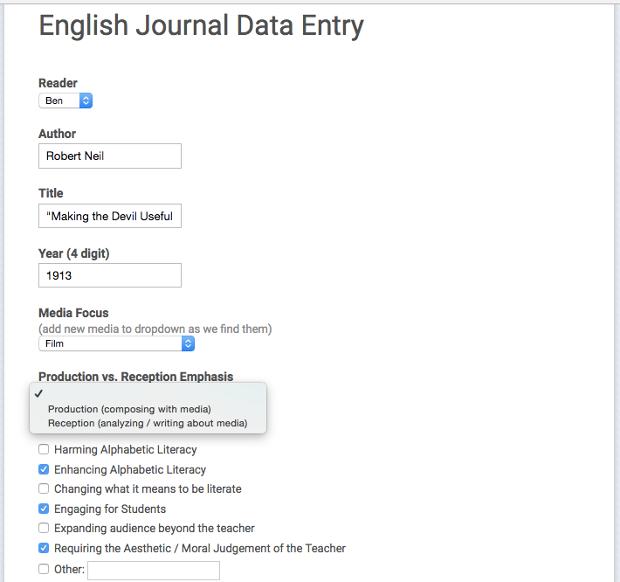
Figure 1. Screenshot of Google Form devised for data input.
Given the historic and ongoing inequalities of access that permeate educators' uses of technology (Banks, 2005; Hawisher & Selfe, 2004), we thought it important not to privilege the use of particular expensive tools but rather to embrace an inclusive definition of media production that included students' composing in new media genres (e.g., the dramatic film, the radio broadcast, the television commercial) using whatever tools they had available. Although we coded "media production" and "media reception" as mutually exclusive categories, it is important to note that there were some articles that blended both approaches (and indeed we see this blending as productive). When we coded an article as "reception," this designation meant that there was either no mention of students composing media texts and/or media production was mentioned in passing in a sentence or two without any substantive development. If we coded an article as "production," this meant that either the entire article focused on media production or that the article described a mix of reception and production activities but (at the very least) it described those production activities in some detail.
In addition to coding for "production" versus "reception" emphases, we also coded for pervasive commonplaces about "new media" that we found in the articles. We follow Ian Barnard (2014) in defining commonplaces as "taken-for-granted or taken-as-axiomatic understandings" (p. 3) that undergird a particular pedagogical approach. Uncovering some of the most prevalent commonplaces about new media that have influenced English studies pedagogy over time can help us critically recognize and re-evaluate the common ideological assumptions that have both constrained and enabled our field's engagement with new technologies. With our coding scheme, we tracked six commonplaces about new media that were particularly pervasive across the corpus, noting moments when the articles implicitly or explicitly argued that new media were:
- Engaging for students
- Harming alphabetic literacy
- Enhancing alphabetic literacy
- Changing the nature of literacy
- Expanding audiences beyond the teacher
- Requiring the aesthetic and/or moral judgment of the teacher
Many of these commonplaces were referenced simultaneously within individual articles so they could not be coded as mutually exclusive categories. It's important to note that we refined our coding scheme for commonplaces in response to data we noticed as the process unfolded; for example, during our reading of the 1930s issues of English Journal, we noted that "requiring the aesthetic / moral judgment of the teacher" was a pervasive argument about new media in the articles, so we added this criteria to our coding scheme and reviewed the earlier articles to account for it.
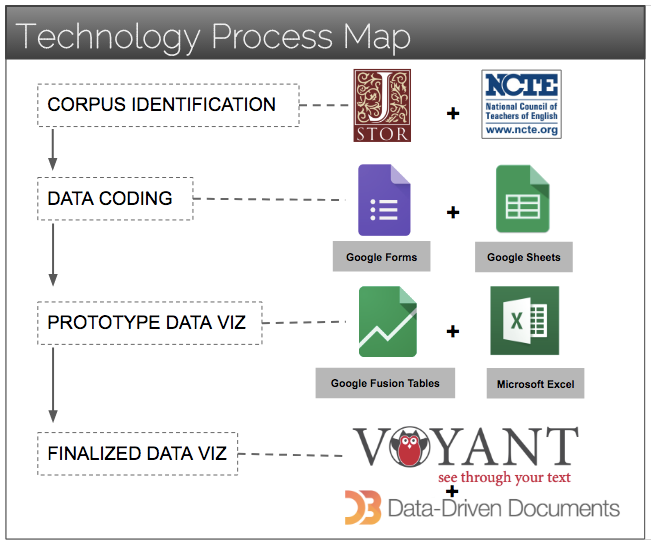
Figure 2. Screenshot of various software used at different stages of our process.
Visualization and Coding Tools
After coding, we used Google Fusion tables to begin to analyze our data, and then we used Microsoft Excel to develop protoypes of our data visualizations. We next employed the D3 Javascript library to design interactive web visualizations that enable users to explore our data in diverse ways (e.g., zooming in on particular years, comparing differing variables). For example, all the timelines in the "zooming in" section allow users to hover over an individual year and view all article titles and corresponding authors that we coded in that particular year for a particular category.
To gain a more high-level view of our corpus, we also used the textual analysis application Voyant to quantitatively code and visualize the most frequent words appearing in article titles in our corpus—taking inspiration from Mueller's (2012b) work visualizing word frequency in CCCC chair addresses. In making our title word clouds, we cleaned up the dataset by conflating variants of commonly occurring word forms under a single stem or headword (e.g., singularizing plural forms, such as changing all instances of "computers" to "computer" to create a larger grouping). Additionally, we used Voyant's default stopword list to filter out noise (e.g., overly common words, prepositions, articles); we also manually excluded the omnipresent word "English" from the title dataset. Although we recognize that word clouds of titles offer a very high-level and ultimately quite limited view of the corpus, we still contend that investigating recurring words in titles can help us interrogate what key terms have been most strongly associated with new media pedagogies over time. In future iterations of this project, we plan to employ machine reading to quantitatively analyze the full text of all the articles; however, the inconsistent scanning quality in the JSTOR archive will require a good deal of data clean-up before a machine reading approach could be fruitful.
Historical Methodologies as Terministic Screens
Despite our work to enact a systematic methodology of data coding, we do not wish to suggest that our distant reading methodology is any more rigorous, objective, or truthful than a narrative-based case study approach. Just as conventional forms of historical storytelling necessarily involve ideologically-loaded processes of selection and exclusion (White, 1973), so too does distant reading reveal certain realities to the exclusion of others. Even though we adopted a systematic method of coding and developed a shared understanding of how to employ it, we are aware that another pair of historians might have coded our dataset very differently.
Although we do not wish to argue for the objectivity of distant reading, we personally have found that adopting distant reading methods has enabled us to employ a more inductive and iterative methodology of historical interpretation. When we wrote our aforementioned solo-authored historical books using narrative case study approaches (McCorkle, 2012; Palmeri, 2012), we each started with a clear argument in mind and then marshalled textual evidence to support it. By contrast, with this project, we simply started with an archive we knew was interesting, and we didn't even begin to formulate some tentative hypotheses about it until after we had systematically coded 50 years' worth of articles. Of course, our coding scheme itself constrained what we could see, but it did usefully enable us to keep reading without moving quickly to interpretation. Indeed, in quite a few cases, our coding process revealed patterns that we never consciously sought to find or patterns that upset some of our default assumptions about the field.
Although we seek to demonstrate that distant reading can reveal patterns that might not otherwise be recognized, we also think it is important to remember that distant reading cannot definitively explain why these patterns occurred or what they mean for the future of the field. In many ways, the interactive graphs we present raise more questions than answers and we think this is a good thing. In our longer, born-digital book project (in progress), we seek to combine our distant reading with close reading of journal articles and contextual materials to offer a more multivalent understanding of how English studies has shaped and been shaped by new media technologies over the past 100 years. In this article, however, we focus primarily on presenting visualizations of our findings as heuristics that can enable scholars to ask different kinds of questions about the historical formation and evolution of our field. While we offer some interpretations of possible explanations for the trends we document, these interpretations are necessarily partial, speculative, and open to revision.