The Problem
While waiting in line for a boxed lunch at the 2018 Thomas R. Watson Conference on Rhetoric and Composition, I stood beside two colleagues who were discussing the most recent episode of Eric Detweiler’s Rhetoricity podcast. “Did you listen to his interview with Christine Tulley?” one asked. “Yes,” the other responded, “I just added her book to my reading list.” Following their conversation, I was able to discern that Tulley’s book was about the writing processes of productive rhet/comp faculty and was published six months ago and—wait, I thought, why haven’t I encountered this book before? I’d been working on a project about the day-to-day working habits of writers, and Tulley’s book was exactly the thread of research that I wanted my own project to be in conversation with. How had I missed it?
Of course, complaints about the rate of scholarly publishing, or the challenges of keeping up with it, are a professional commonplace. There’s always already too much work. But for me, following journal articles hasn’t been a particular challenge: Many publishers offer email alerts or feeds for following new issues. Between those publisher resources and my print subscriptions, I generally feel aware of new article-length works in my areas of interest. Books, however, pose a different problem.
Ideally, my university library or a larger aggregator like Worldcat would offer a way to follow particular publishers or series or keywords. But books in rhetoric and composition fall under a number of subject areas and library call numbers, and they are published by a diverse set of presses and imprints—including important born-digital venues that aren’t immediately indexed in print-centric databases and library catalogs. The same holds for booksellers like Amazon, which have categories for the field’s subject areas, but whose listings tend to highlight a few highly visible university presses.
Instead, the most reliable way to discover new books is through email marketing lists from publishers and from social media. Both of these, however, present a signal-to-noise problem. For me, the email inbox is a slot machine of work-, personal-, and advertising-related communications, and adding to its mess isn’t an ideal way of finding new information or referring back to it. Likewise, my social media feeds have grown into an impenetrable mess as platforms have matured and relied more on algorithms and advertising dollars. Searching for a new book announcement on Twitter often requires me to wade through current events, conference live tweets, ongoing conversations, advertisements, and more. The untended garden of today’s social media simply isn’t an ideal way to find a single, specific piece of information.
As I stood in line for a Watson lunch and thought about this problem, it seemed solvable with a small, focused project—something for which our field has many models. As a graduate student I relied on CompPile and the Tech Comm Eserver, both of which were incredible databases of publications in the field (and the latter of which, as I write this article, has sadly gone down). Jim Ridolfo’s Rhetmap has helped many graduate students track job postings in the field, offering both a spreadsheet of job ads and a mapped visualization of job locations. And there are countless models of community-built and volunteer-run publication platforms, from journals to monographs. In many of these cases, as George Pullman and Baotong Gu (2013) noted, “technical and professional writers and teachers have come by different means to the same conclusion: that if you want something done right when it comes to information technology and writing instruction and research, you have to do it yourself” (p. 1). Following this advice, I built Rhetorlist—a simple website that collects and lists new book releases in the field. I identified a small problem, learned a bit about a specific technology (JSON, or JavaScript Object Notation) that could help me solve it, and built a website around the JSON data.
This type of work was once the norm in computers and writing—an enthusiasm, perhaps, that has moved to the broader field of the digital humanities, especially when it comes to external funding (Ridolfo & Hart-Davidson, 2015, p. 4)—but seems less so today. Older projects have disappeared or stopped working. Writing software is (with few exceptions) no longer made by writing researchers. And we’ve outsourced many professional tools and resources to companies like Interfolio. This shift is understandable: Modern software development is complex, and third-party vendors are often better equipped to handle the large-scale challenge of creating software and technical solutions. But there are still opportunities for intervention, and there’s much good work to be done by developing small projects that do one thing well.
In the following sections, I make a call for more of that work, and—based on my experience building Rhetorlist, as well as my work with Computers and Composition Digital Press—introduce a framework for small, meaningful projects. First, I’ll briefly point to our field’s histories with software and digital tool development. Next, I will note the contemporary challenges that have perhaps stifled some enthusiasm for designing new projects. Following that, I’ll talk briefly about open standards, about my specific approach to building Rhetorlist, and about three principles that (I hope) can help others think about similar projects. In short, if we see professional problems as creative opportunities—and build inclusively from them—we can make valuable contributions that echo the field’s early interest in and experimentation with computing technologies.
Histories, briefly
Computers and writing specialists are part of a long lineage of teachers and researchers who have asked questions about software design and use. That lineage, which grew from the 1970s arrival of the microcomputer on university campuses, is thoroughly grounded in innovation, creativity, and—most importantly—a focus on the user. For example, the early chapters of Gail E. Hawisher, Paul LeBlanc, Charles Moran, and Cynthia L. Selfe’s (1996) Computers and the Teaching of Writing in American Higher Education, 1979-1994: A History described the initial growth of grammar and style checkers, which “promised to alleviate some of the teachers’ dullest and most burdensome work” (p. 37), but which were followed by process-oriented software—developed by writing researchers—that drew from the field’s knowledge and best practices: James Strickland’s FREE program based on Peter Elbow’s approach to freewriting, or Ruth Von Blum, Michael Cohen, and Lisa Gerrard’s WANDAH, which offered a number of planning and invention activities (p. 43). As Hawisher et al. wrote, “Despite challenges faced by the field during this time, or perhaps to a degree, because of these challenges, those of us in the field who worked with computers during this early period remember it as a time of intense excitement and hope” (p. 52).
As the field moved into the 1990s, however, that excitement soon gave way to frustration. English departments either didn’t have a way to evaluate software development or were “outright hostile” to it (Leblanc, 1993, p. 89), and many projects were sold to textbook publishers who used the software as a free value-add to book sales and who wouldn’t invest in updates (Hawisher et al., 1996, p. 100). The 2000s would offer new and more user-friendly means of creating digital projects (especially born-digital scholarly texts), but many of the tools used to make them—particularly Flash and Shockwave—have fallen out of favor and left a wake of now-unusable artifacts. If you’ve read an article in an academic journal and typed in the URL of a digital reference only to find that thing missing or inaccessible, you’ve probably felt some distrust in the permanence of digital objects. And if digital projects feel brittle or tenuous or institutionally devalued, then it would be no surprise to see our collective professional energy shifting elsewhere.
But instead of making us wary, these challenges and disappearances should prompt us to ask how digital projects might better align our tools with our professional needs and ethics. As Paul LeBlanc (1993) wrote, “in an age of electronic literacy, the software we and our students use will be a significant part of our pedagogy and may or may not embody a theory or ideology to our liking: thus we have an important stake in its development and design” (p. 147). Responding to LeBlanc’s call that writing teachers should build software that represents the field’s best ideas, Michael McLeod, William Hart-Davidson, and Jeffrey Grabill (2013) argued that “if we are making an honest assessment of the work of writing teachers and researchers, we can conclude that very few have taken up LeBlanc’s challenge” (p. 8) and that “the pattern of scholarship in computers and writing and rhetoric/composition has been to employ existing technologies to modify writing pedagogies, and vice versa” (p. 9). ELI (Michigan State), <emma> (University of Georgia), and My Reviewers (South Florida) are all examples of how writing teachers and researchers have worked to build teaching tools that align with our professional knowledge. How can we find inspiration in these tools, and if we choose to build our own, what challenges might we face?
Contemporary challenges
If computers and writing scholars drove a culture of tool experimentation and software development in the 1980s and ’90s, why is it less the case today? I would point to three possible reasons.
First, as the web and software development have matured, so have the literacies required. Although it is still possible to make a website with only a basic knowledge of HTML, a modern, interactive, and accessible website (or web app) requires an understanding of CSS, JavaScript, responsive design, media queries, and more. And this extends to templates and frameworks as well: even the currently popular HTML5 UP design templates require the user to understand CSS frameworks and grid-based layout. Said simply: These tools aren’t beginner friendly.
There are, of course, WYSIWYG (what you see is what you get) tools and platforms like Wix, Weebly, Wordpress, Squarespace, and others. These platforms work well for portfolios and hobbyist sites, but they present significant preservation challenges for any kind of professional application. Most of these services store user content in some kind of database, making it difficult to read, retrieve, or export the raw content (especially if the software locks the export features behind a paywall). And those tools are often mired in monetization strategies that either hide features and complexity from users in the name of a beginner-friendly user experience or lock in the content so that it is difficult to reuse or repurpose.
Connected to this is the rise of institutional (or “enterprise”) software—especially within the university—and the creeping scope of tools whose solutions are sold to universities but whose priorities aren’t always aligned with our professional values. This is a complex problem. For example, learning management systems have been critically read and critiqued in the field (Purdy, 2005; Reilly & Williams, 2006; Salisbury, 2018;) but they do have upsides: they provide students with a familiar interface across all courses, they offer accessible and mobile-friendly functionality, and they facilitate secure grade storage and messaging. But other proprietary tools have also come from corporate vendors whose software doesn’t align with the field’s priorities, knowledge, and sense of best practices (Turnitin being a key example of this, cf. Marsh, 2004; Vie, 2013). Altogether, these tools might lead to software fatigue for some faculty—a sense that these many applications are getting in the way of work, and that it would be perhaps easier to fall back to a more minimal (or perhaps even analog) set of tools.
There are also, as I mentioned earlier, the fraught histories of digital DIY work in the field. The beloved journal that disappeared. The aging born-digital piece that requires an outdated or difficult-to-get browser plugin. The promising software application that was sold to a software publisher and promptly forgotten or mismanaged. Or the many blogs and web resources that now sit idle. I don’t think there’s anything wrong with ephemerality—some things can and should come and go. I do, however, think there is room for small, professional tools that are built with simplicity and sustainability in mind. Digital objects and spaces that can be sites of pedagogy, professional generosity, and useful functionality. So how can we build these tools? What should we draw on? What do we have to know?
Rhetorlist, specifically
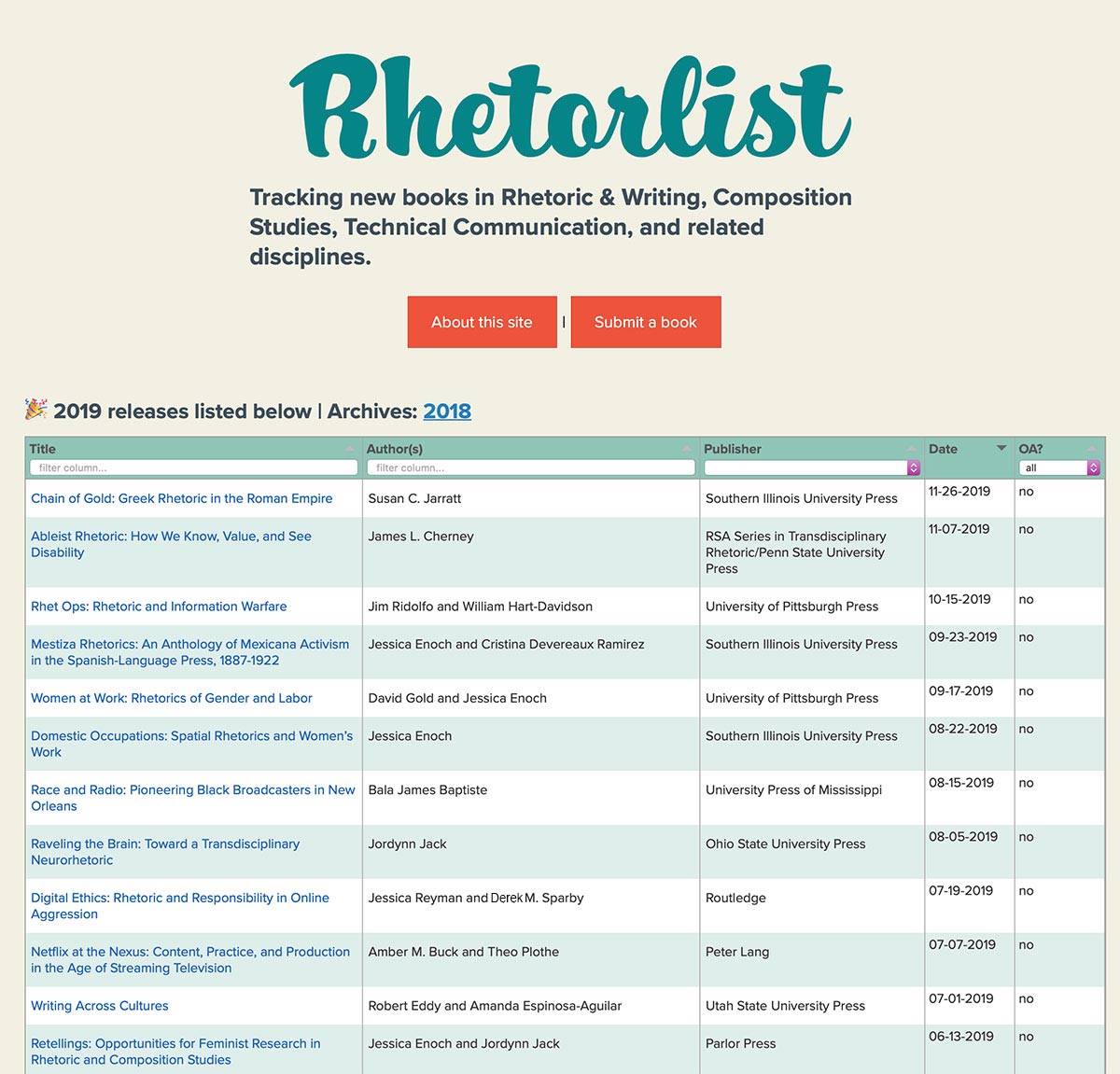
Although I’m not a software developer, I do have proficiency with web development, and the problem of tracking new books seemed like one that could be solved with a simple website. To do so, I needed to collect the data—perhaps by asking publishers to contact me when they release new books, and infrequently doing a manual sweep of publisher websites. Because there are fewer books published than articles, the labor of data collection seemed like a manageable task. But how to build the site? I could make something in plain HTML, or perhaps in a content management system like Wordpress, but I wasn’t enthused by the prospect of manually adding new code every time a book is published. Likewise, I wanted to keep the Rhetorlist data separate from the site and reusable in a way that might be helpful to others. Following Karl Stolley’s (2016) argument the we should use “human-readable, standards-compliant computer languages for specific tasks such as markup, design, scripting, and programming” (n.p.), I experimented with the JSON file type. (The following discussion gets a bit technical, but stay with me.) JSON is a plain text file format for storing data, and unlike other database models, JSON is very easy to design and read. Each piece of data is called an “object,” and each object is made up of “name/value pairs.” These pairs can be structured in any manner you choose—the data is freeform. For example, here’s how I structured a book object in JSON format for Rhetorlist:
{
"title": "Rhetorical Code Studies",
"author": "Kevin Brock",
"publication date": "03-01-2019",
"publisher": "Sweetland Digital Rhetoric Collaborative/UMich Press",
"publisherURL": "https://www.press.umich.edu/10019291/rhetorical_code_studies",
"openAccess": "yes",
}Even if you don’t know the specific syntax of a JSON file, you can probably read the code above and understand the information being stored. But let’s demystify this a bit further. The above example has six name/value pairs, and each pair is separated by a colon. The text on the left side of the colon is the name, and it describes the value that follows on the right side of the colon. In the above example, this object has a title value of “Rhetorical Code Studies.” Each pair (except the last) ends with a comma. The names in this example are the types of data that I decided to show on Rhetorlist, but they could be anything—much like columns in a spreadsheet. A series of name/value pairs is wrapped in braces, and together everthing within braces is an object—or, in the case of Rhetorlist, a book. The JSON files that drive Rhetorlist are just books as objects, one after another.
{
"title": "Writing Across Cultures",
"author": "Robert Eddy and Amanda Espinosa-Aguilar",
"publicationDate": "07-01-2019",
"publisher": "Utah State University Press",
"publisherURL": "https://upcolorado.com/utah-state-university-press/item/3675-writing-across-cultures",
"openAccess": "no"
},
{
"title": "Ableist Rhetoric: How We Know, Value, and See Disability",
"author": "James L. Cherney",
"publicationDate": "11-07-2019",
"publisher": "RSA Series in Transdisciplinary Rhetoric/Penn State University Press",
"publisherURL": "http://www.psupress.org/books/titles/978-0-271-08468-8.html",
"openAccess": "no"
},
{
"title": "Rhetoric and Demagoguery",
"author": "Patricia Roberts-Miller",
"publicationDate": "02-05-2019",
"publisher": "Southern Illinois University Press",
"publisherURL": "http://siupress.siu.edu/books/978-0-8093-3712-5",
"openAccess": "no"
}
A format like JSON is appealing because of its simplicity. Conceptually, it is easy to manipulate: When a reader visits rhetorlist.net, the website loads all of the JSON objects (the books) from a text file on the server and arranges their name/value pairs in a table. Because JSON is just text, it’s easy to add to, change, or manipulate in a simple text editor. More objects can be added, or more pairs can be added to existing objects with just a bit of repetitive labor (or automation). And the data can be endlessly repurposed. Someone else could use the Rhetorlist JSON files to visualize the number of books published across time or the number of new books published by month.
When I learn of a new book—from a publisher email, from a manual sweep, or from a reader submission—I add a new object to this year’s Rhetorlist JSON file and upload it to the server. The next time a reader visits the site, they see it in the Rhetorlist table. Incrementally, over time, I hope the site can serve as an archive of our field’s long-form publications. And because the underlying data is all plain text and open source, anyone can take the JSON files and repurpose them. If I were no longer able to update the site, someone else could upload the code to their own server and maintain the project or move it forward.
Of course, we all know that it isn’t that easy. I’ve offered a brief description of JSON, and with practice I’m sure you could write your own JSON file in no time, but rolling it into a functioning project requires several kinds of antecedent knowledges: How to make a website, how to build a table from the JSON data, how to upload it to a server, and how to circulate the source code so that others may reuse the project and extend it into new areas. My thesis here isn’t that everyone should know how to do this.
I do, however, see value in selectively learning how some of these technologies work and then—through collaboration—using them to solve small problems. JSON is compelling because it’s human-readable and preservable and reusable. It might look imposing at first glance—all those computer-syntax punctuation marks!—but it is learnable and usable. Together, we should further study and collaboratively build digital resources that are accessible, preservable, extendable, and that do one thing well.
So how do we discover these possibilities, and how do we determine if they are a fit for our professional knowledges and expertises?
Three principles for small, meaningful projects
1. Find a small, solvable problem
Early software developers valued doing one thing well, suggesting that the best approach was to “build afresh rather than complicate old programs by adding new ‘features’” (McIlroy, Pinson, & Tague, 1978, p. 1902). I suggest we can use this perspective as a way of seeing problems and identifying places where a discrete solution can offer value to the field. We should search for small-scale projects that do one thing well, responding to a discrete and solvable problem in a manner that is inclusive and accessible.
This might sound like common sense, but I think it is deceptively challenging. We work on complex problems, and we work with complex technologies. The typical learning management system is an example of this: It has to provide an accessible interface, it has to communicate sensitive data securely, and it has to address an endless number of possible use cases across different curriculum and institutional needs. LMSs have been much maligned, I think, because they’re a single tool that is designed for too many different use cases across too many different types of users and institutions. But the LMS also responds to a problem that’s too challenging for a small group to solve.
Instead, we might draw inspiration from what Cheryl Ball, Tarez Samra Graban, and Michelle Sidler (2013) call “boutique data,” or “data sets [that] are often small and built from local contexts, but when combined with other such sets, they are rich in potential new sources of inquiry and knowledge” (para. 7). Similarly, a boutique project would solve a small problem with discrete solutions within small or local contexts. The field’s many online journals and born digital publication spaces are one model of this, and they show how selective focus and volunteer labor can expand our scholarly reach.
To find these boutique opportunities, we might start searching for friction. In my work with Derek Van Ittersum, we’ve spoken with users and software developers who often describe friction—the moments when something (often a tool) disrupted, or got in the way, of work. Friction can be the moment when a frustrated user walks away. But it can also signal an opportunity, and it can act as a lens for finding problems and places where a small project can make a meaningful intervention.
In my case, that was the friction of finding new books. I suspected I wasn’t alone in this, and I wondered if others had strategies for following book releases. I sent several emails to colleagues, asking “does a solution to this problem exist? Did I miss it?” Others underscored the same friction I felt, and several pointed to places where they looked for new books: Amazon, listservs, social media. But no one knew of a single place where this information was collected. I felt that my friction was shared, but that it also had a generative possibility.
A search for small, solvable problems reorients us toward the creative spirit of computers and writing researchers in the 1980s and ‘90s. We should return to and draw on that spirit, and we should use that creativity to realign our tools and resources with our professional values.
2. Work from professional values
So how do we find these small, solvable problems? One method involves looking for tools, technologies, systems, or absences that run counter to our professional values. Jim Ridolfo’s Rhetmap is one example of this. Rhetmap emerged from a 2012 conversation about the role of the Modern Language Association Job List, in which Dave Parry (2012) claimed that “the MLA has set itself up as the primary knowledge broker in the trafficking of information about jobs” (para. 10) and Collin Gifford Brooke (2012) added that “the 'service’ they currently provide is little more than a text file and the Find command from the Edit menu of a word processor” (para. 12). In collecting job advertisements and mapping them on an open, publicly available website, Rhetmap alleviates some of the friction (or, perhaps, the paywall) of searching for jobs, and it moves the job advertisement away from a membership-driven professional association and into a volunteer-based professional gift economy. It is a small, meaningful project.
Similarly, part of Rhetorlist’s exigence sits within the varied spaces in which our books are distributed. Although Amazon and Worldcat and Goodreads surface new print books, they often miss the digital, open access books published by venues like the WAC Clearinghouse, Intermezzo at Enculturation, and Computers & Composition Digital Press. When I constructed the JSON structure of Rhetorlist, I added an Open Access field to help readers easily discover open access titles and, hopefully, encourage authors to consider working with an open access publisher.
By searching for these places where the available tools or resources don’t align with our professional values, we can find opportunities for small, meaningful projects. In doing that work, however, we need to think inclusively and collaboratively.
3. Build inclusively and collaboratively
It’s easy for calls such as this one to be skills-centric, or to appeal to those who have the institutional resources, background, access, or proficiency to put these projects into action. This is part of the problem with the recurring “everyone should learn how to code” mantra. It privileges those with particular interests, access, and ways of seeing the world, and it obscures how contemporary software development is based on the concept of “projects” that are often built by people with many different types of expertise, from user experience to design trends to low-level programming. This technological work—even at the level of small projects—best happens collaboratively and inclusively. So how do we adopt that mindset?
Although I initially made Rhetorlist as a sort of “single author” project, I drew on the advice and guidance of several colleagues. Now, as I move forward with the site, I will soon collaborate with a graduate student who will help me add data from past years to the site. In a similar project (Lockridge, Paz, & Johnson, 2017) I used the preservation of old Kairos texts as a pedagogical space, and I think projects like Rhetorlist have similar potential. They help us see our professional tools, resources, and histories as spaces in which we actively teach and learn together.
Rhetorlist, by tracking new books in the field, poses another problem: What exactly is the field? Instead of drawing arbitrary lines around what I saw as the field, I instead followed a suggestion from Ridolfo and added a Google Form to the site. This, I hoped, would allow authors to alert me when they published something new, but it would also let site visitors suggest books I’ve missed or presses I didn’t know about. It presents the site not as something rigid or bound to a particular set of disciplinary constraints, but rather a set of texts that visitors see as useful or a collection of works that authors want to be in conversation with. The site is better and more valuable, I hope, with the suggestions of each new visitor.
See the creative potential of new technologies
Most importantly, perhaps, I’m asking us to better imagine the creative potential of technologies. It’s easy, in 2020, to adopt a cynical view of technology: the mismanaged social networks, the spread of venture capital and the erosion of privacy, the broad adoption of corporate-minded software throughout the university.
But I think it’s important to remember that there’s still much potential and beauty and collaboration to be found in this space. The field’s many born-digital publications are a reminder of this. We have wonderful online venues of scholarship, and many of them were built to push against values that aren’t aligned with the field’s, to highlight areas of inquiry that traditional print venues have overlooked, or to serve as inclusive teaching and mentoring spaces for the creation of born-digital work. We should embrace that spirit and extend it into new areas—imagining how small digital projects might allow us to solve problems and better align our tools with the ways we want to work and collaborate.
References
Ball, Cheryl, Graban, Tarez Samra, & Sidler, Michelle. (2013). From big data to boutique data. The Gayle Morris Sweetland Digital Rhetoric Collaborative. Retrieved from http://www.digitalrhetoriccollaborative.org/2013/11/12/from-big-data-to-boutique-data/
Brooke, Collin Gifford. (2012). Migrating the MLA JIL from list to service. cgbrooke.net. Retreived from http://www.cgbrooke.net/2012/09/19/migrating-the-mla-jil-from-list-to-service/
Hawisher, Gail E., LeBlanc, Paul, Moran, Charles, & Selfe, Cynthia L. (1996). Computers and the teaching of writing in American higher education: 1979–1994: A history. Norwood, NJ: Ablex.
LeBlanc, Paul. (1993). Writing teachers writing software: Creating our place in the electronic age. Urbana, IL: NCTE.
Lockridge, Timothy, Paz, Enrique, & Johnson, Cynthia. (2017). The Kairos preservation project. Computers and Composition, 46, 72–86.
Marsh, Bill. (2004). Turnitin.com and the scriptural enterprise of plagiarism detection. Computers and Composition 21(4), 427–438.
McIlroy, Malcom Douglas, Pinson, Elliot N., & Tague, Berkeley A. (1978). UNIX time-sharing system: Foreword. The Bell System Technical Journal, 57(6), 1899–1904.
McLeod, Michael, Hart-Davidson, William, & Grabill, Jeffrey. (2013). Theorizing and building online writing environments: User-centered design beyond the interface. In George Pullman & Baotong Gu (Eds.), Designing web-based applications for 21st century writing classrooms (pp. 7–18). Amityville, NY: Baywood.
Parry, David. (2012). The future of the MLA job list. Outside the text. Retrieved from https://outsidethetext.com/posts/the-future-of-the-mla-job-list/
Pullman, George, & Gu, Baotong. (2013). Introduction. In George Pullman & Baotong Gu (Eds.), Designing web-based applications for 21st century writing classrooms (pp. 1–6). Amityville, NY: Baywood.
Purdy, James P. (2005). Calling off the hounds: Technology and the visibility of plagiarism. Pedagogy, 5(2), 275–296.
Reilly, Colleen, & Williams, Joseph John. (2006). The price of free software: Labor, ethics, and context in distance eduction. Computers and Composition, 23(1), 68–90.
Ridolfo, Jim, & Hart-Davidson, William. (2015). Introduction. In Jim Ridolfo & William Hart-Davidson (Eds.), Rhetoric and the digital humanities (pp. 1–12). Chicago, IL: University of Chicago Press.
Salisbury, Lauren E. (2018). Just a tool: Instructors’ attitudes and use of course management systems for online writing instruction. Computers and Composition, 48, 1–17.
Vie, Stephanie. (2013). A pedagogy of resistance toward plagiarism detection technologies. Computers and Composition, 30(1), 3–15.